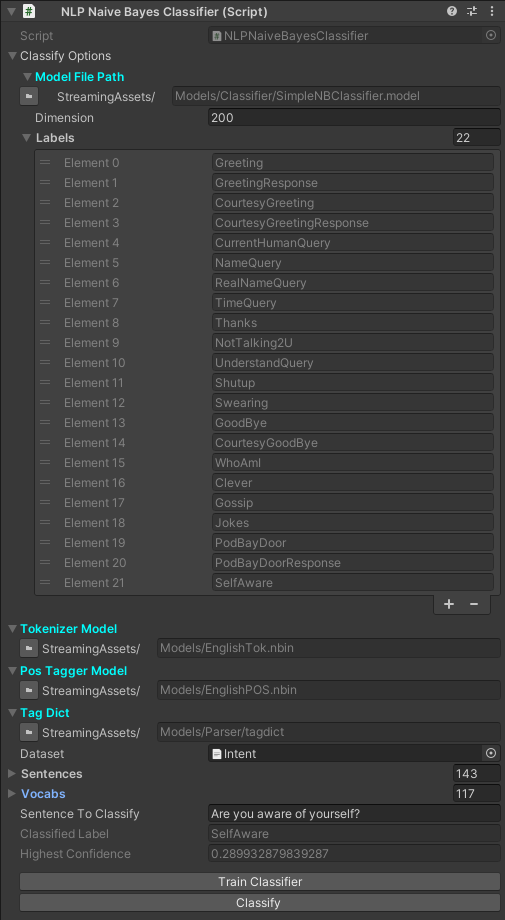
Topical Classifier¶
A topical classifier classifies a sentence into a category.
Multinomial Naive Bayes Classifier¶
A multinomial naive bayes classifier is good at classifying short sentences.
Example¶
In this example, we train a multinomial naive bayes classifier to classify 22 categories of sentences. The script below decodes a JSON file as the training data.
using System;
using System.Collections.Generic;
using UnityEngine;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using Voxell;
using Voxell.Inspector;
using Voxell.NLP;
using Voxell.NLP.Classifier;
using Voxell.NLP.Tokenize;
using Voxell.NLP.PosTagger;
using Voxell.NLP.Stem;
public class NLPNaiveBayesClassifier : MonoBehaviour
{
public ClassifyOptions classifyOptions;
[StreamingAssetFilePath] public string tokenizerModel;
[StreamingAssetFilePath] public string posTaggerModel;
[StreamingAssetFilePath] public string tagDict;
public TextAsset dataset;
public List<Sentence> sentences;
public List<string> vocabs;
public string sentenceToClassify;
[InspectOnly] public string classifiedLabel;
[InspectOnly] public double highestConfidence;
private NaiveBayesClassifier classifier;
private EnglishMaximumEntropyTokenizer tokenizer;
private EnglishMaximumEntropyPosTagger posTagger;
private RegexStemmer stemmer;
public void InitializeData()
{
// reset data
sentences.Clear();
sentences.TrimExcess();
classifyOptions.labels.Clear();
classifyOptions.labels.TrimExcess();
// create tokenizer, pos tagger, and stemmer
tokenizer = new EnglishMaximumEntropyTokenizer(FileUtil.GetStreamingAssetFilePath(tokenizerModel));
posTagger = new EnglishMaximumEntropyPosTagger(
FileUtil.GetStreamingAssetFilePath(posTaggerModel),
FileUtil.GetStreamingAssetFilePath(tagDict));
stemmer = new RegexStemmer();
stemmer.CreatePattern();
// generate data
var data = JsonConvert.DeserializeObject<JObject>(dataset.text);
JToken intents = data["intents"];
foreach (JToken intent in intents)
classifyOptions.AddLabel((string)intent["intent"]);
foreach (JToken intent in intents)
{
// convert each sentences into a Sentence class and add it into the list
foreach (JToken text in intent["text"])
sentences.Add(new Sentence(
((string)text).ToLower(),
(string)intent["intent"],
tokenizer, posTagger, stemmer
));
}
}
[Button]
public void TrainClassifier()
{
InitializeData();
// train and save the model
classifier = new NaiveBayesClassifier();
classifier.Train(sentences, classifyOptions);
classifier.SaveModel(classifyOptions);
}
[Button]
public void Classify()
{
if (tokenizer == null)
{
// recreate tokenizer, pos tagger, and stemmer if editor is being refreshed
tokenizer = new EnglishMaximumEntropyTokenizer(FileUtil.GetStreamingAssetFilePath(tokenizerModel));
posTagger = new EnglishMaximumEntropyPosTagger(
FileUtil.GetStreamingAssetFilePath(posTaggerModel),
FileUtil.GetStreamingAssetFilePath(tagDict));
stemmer = new RegexStemmer();
stemmer.CreatePattern();
}
// convert string sentence to Sentence class
Sentence sent = new Sentence(sentenceToClassify.ToLower(), "", tokenizer, posTagger, stemmer);
classifier = new NaiveBayesClassifier();
classifier.LoadModel(classifyOptions);
// take a look at all the vocabs that the classifier stored
vocabs = classifier.words;
List<Tuple<string, double>> result = classifier.Classify(sent, classifyOptions);
classifiedLabel = "";
highestConfidence = 0.0;
for (int r=0; r < result.Count; r++)
{
if (result[r].Item2 > highestConfidence)
{
classifiedLabel = result[r].Item1;
highestConfidence = result[r].Item2;
}
}
}
}